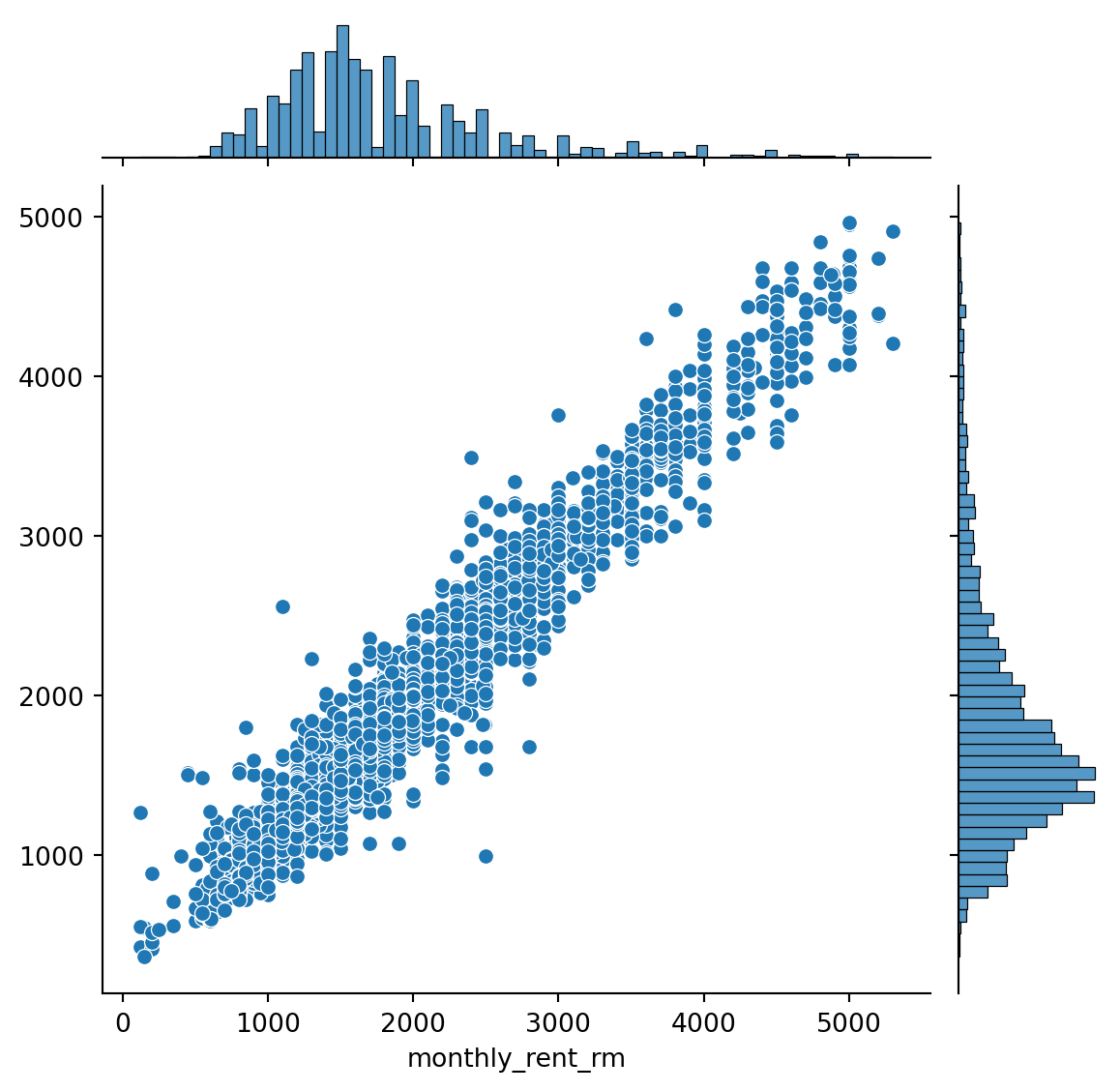
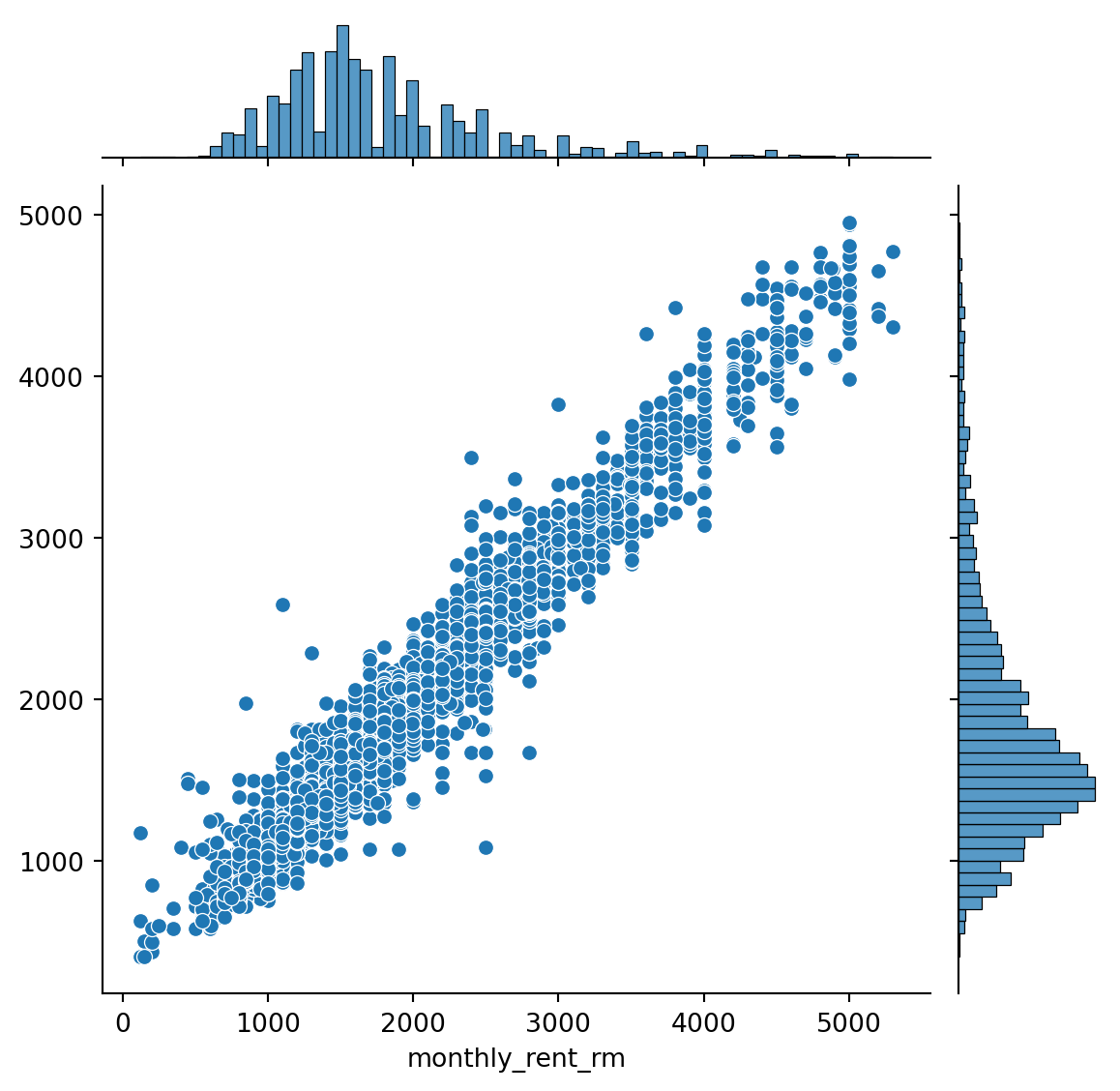
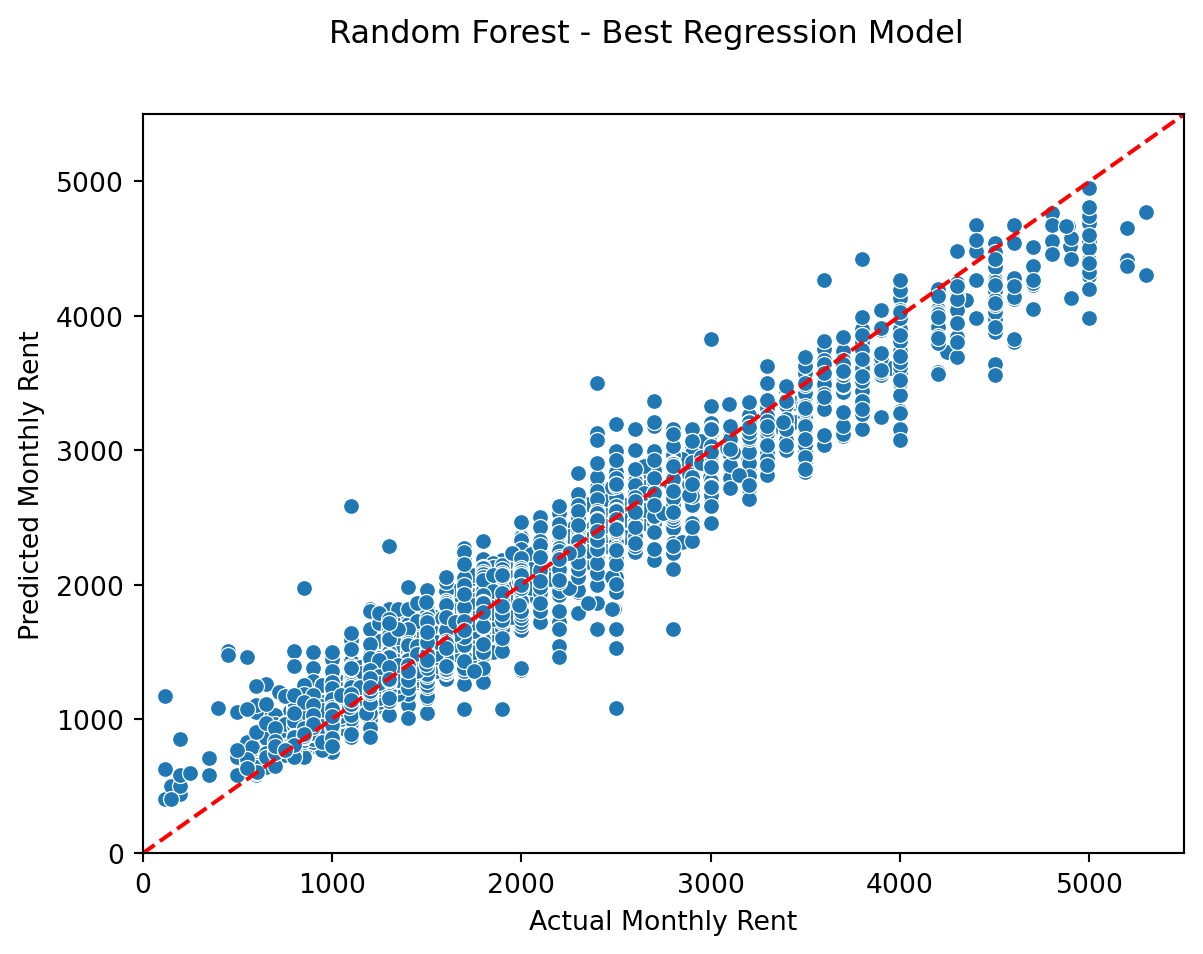
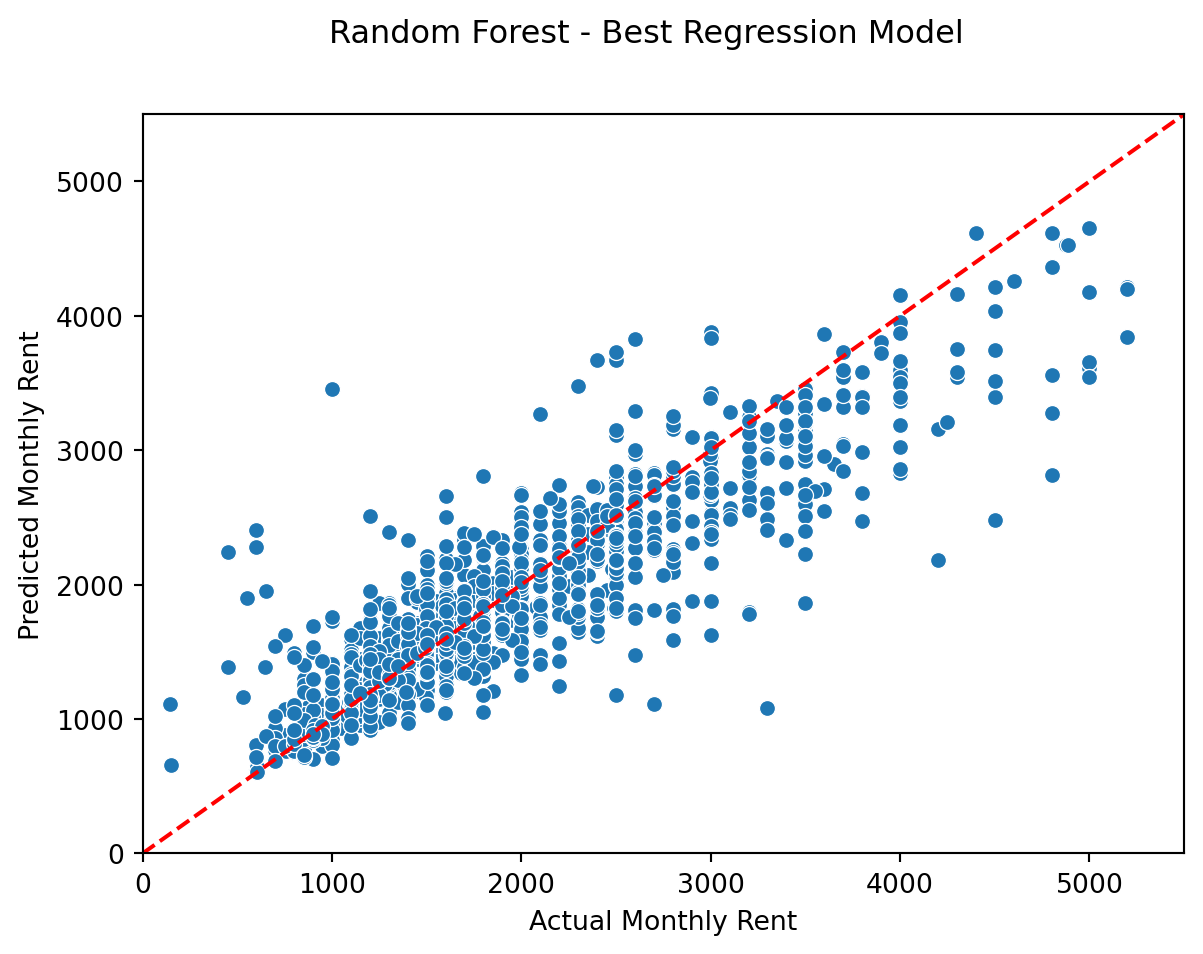
[{'realValue': '', 'id': 'ads_id', 'value': '95301490', 'label': 'id ads'},
{'realValue': 'PPA1M METROPOLITAN KEPONG',
'id': 'prop_name',
'value': 'PPA1M METROPOLITAN KEPONG',
'label': 'Building Name'},
{'realValue': '', 'id': 'developer_name', 'value': '', 'label': 'Developer'},
{'realValue': 'BLOK A PPA1M METROPOLITAN KEPONG MRR2, Kuala Lumpur, Kepong',
'id': 'full_address',
'value': 'BLOK A PPA1M METROPOLITAN KEPONG MRR2, Kuala Lumpur, Kepong',
'label': 'Address'},
{'realValue': '',
'id': 'completion_year',
'value': '',
'label': 'Completion Year'},
{'realValue': '', 'id': 'num_floors', 'value': '', 'label': '# of Floors'},
{'realValue': '', 'id': 'num_units', 'value': '', 'label': 'Total Units'},
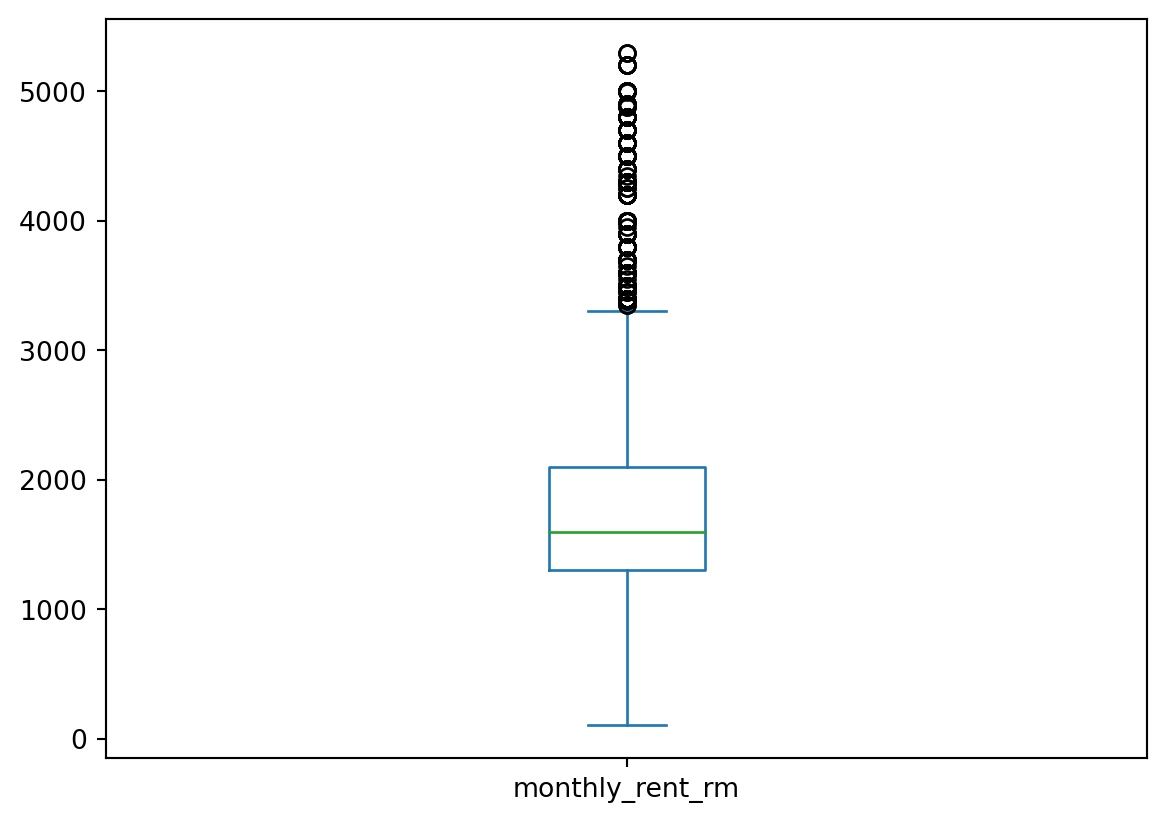
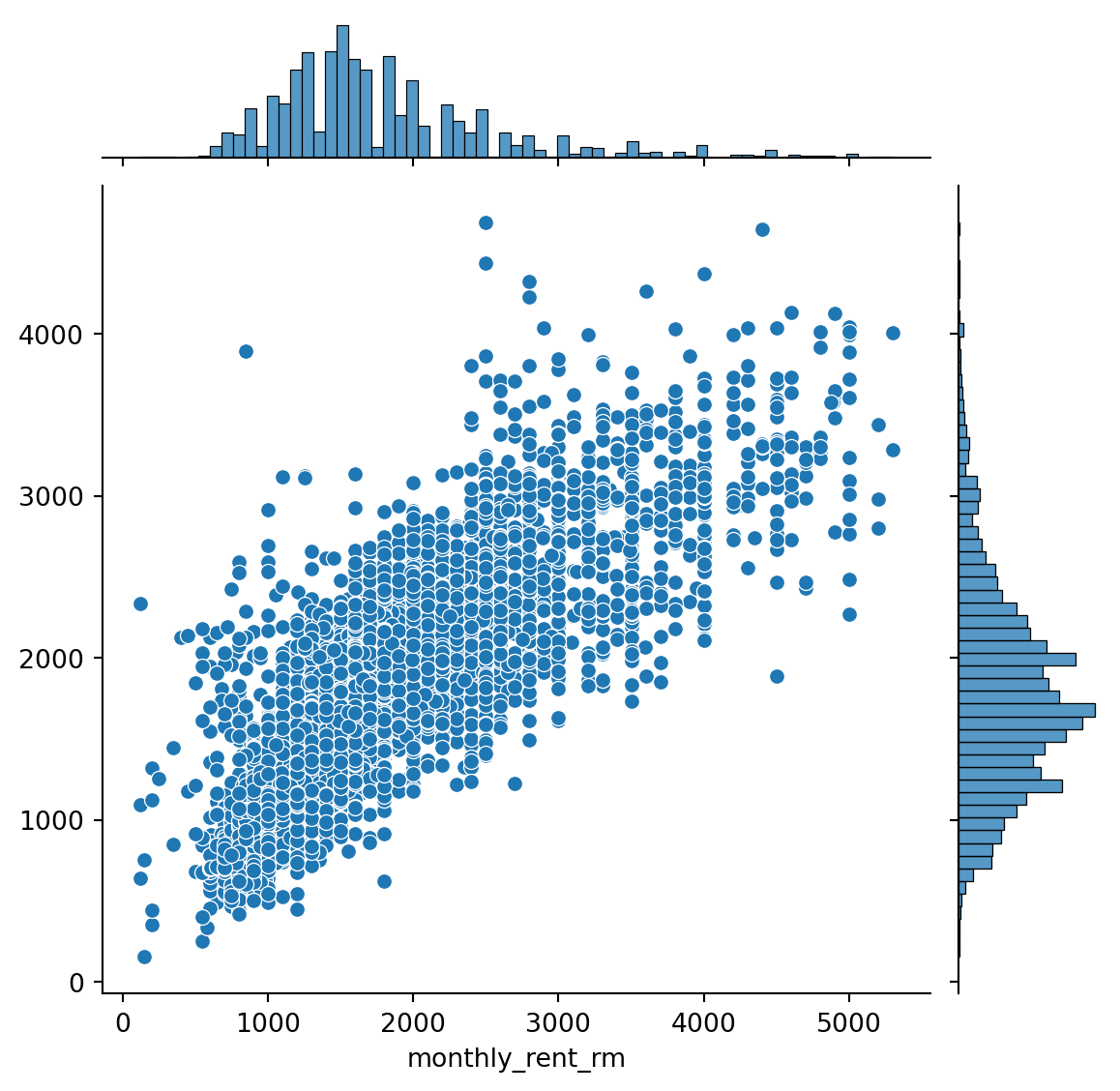
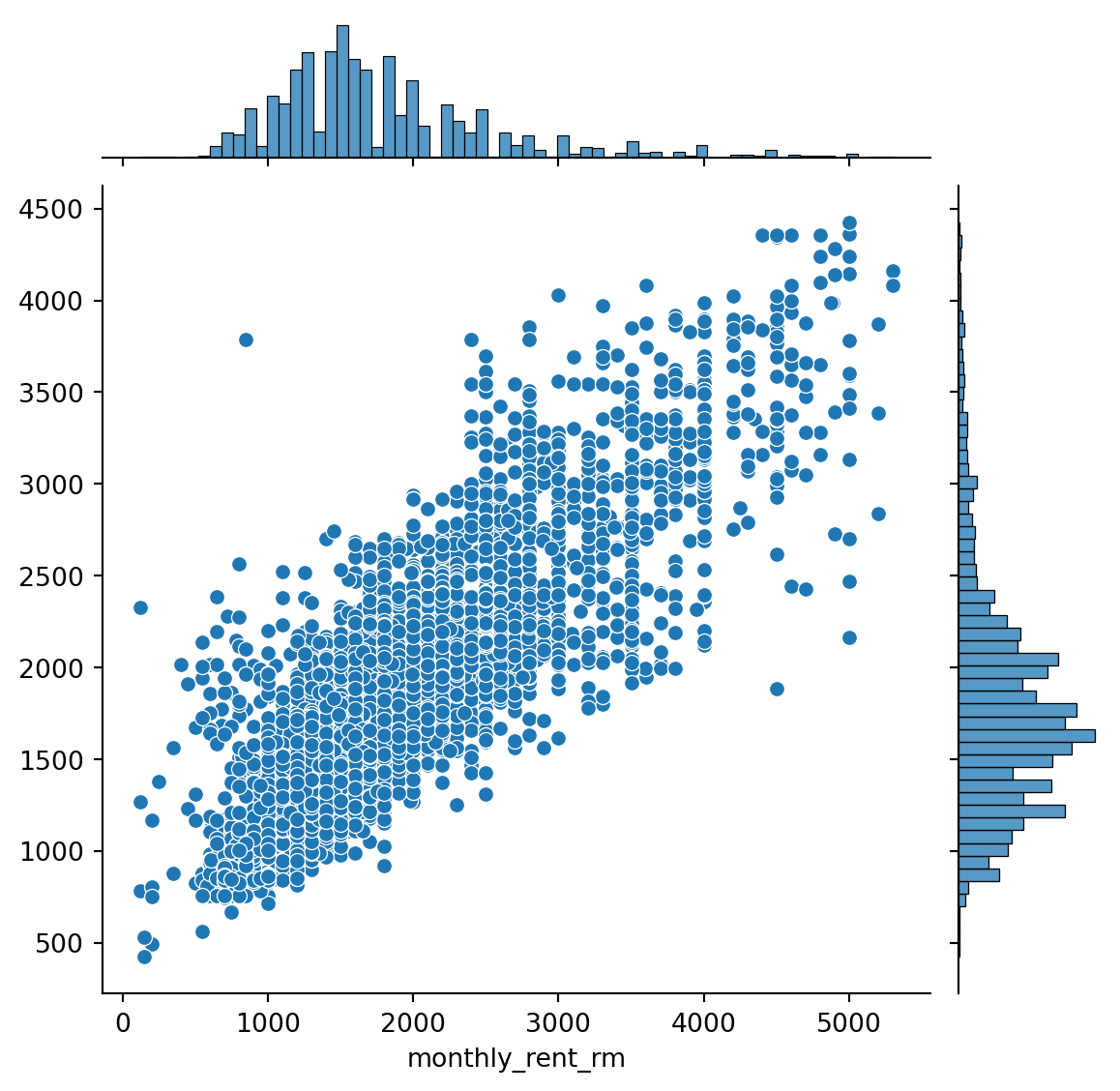
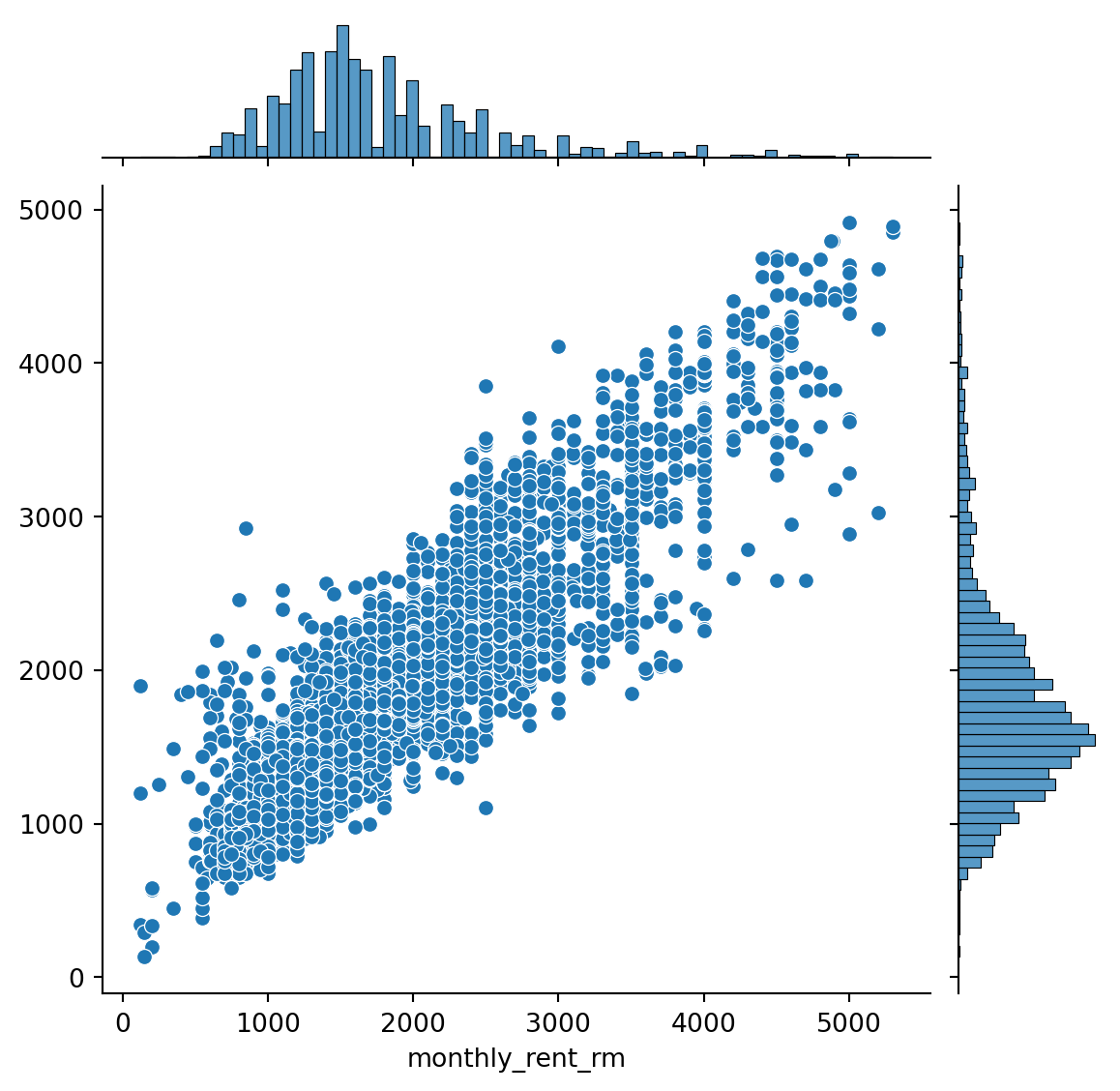
{'realValue': 'RM 1 600 per month',
'id': 'monthly_rent',
'value': 'RM 1 600 per month',
'label': 'Monthly Rent'},
{'realValue': '2020',
'id': 'category_id',
'value': 'Apartment / Condominium, For rent',
'label': 'Category'},
{'realValue': '9',
'id': 'location',
'value': 'Kuala Lumpur - Kepong',
'label': 'Location'},
{'realValue': '1',
'id': 'property_type',
'value': 'Condominium',
'label': 'Property Type'},
{'realValue': '1',
'id': 'floor_range',
'value': 'High',
'label': 'Floor Range'},
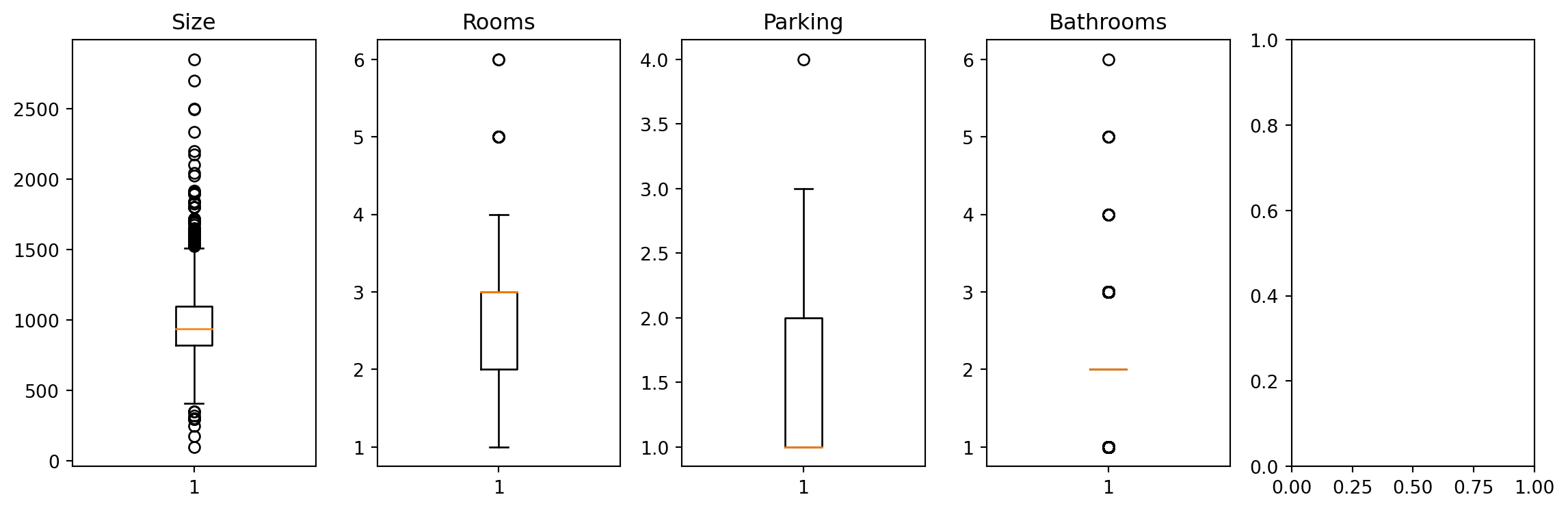
{'realValue': '5', 'id': 'rooms', 'value': '5', 'label': 'Bedrooms'},
{'realValue': '2', 'id': 'bathroom', 'value': '2', 'label': 'Bathroom'},
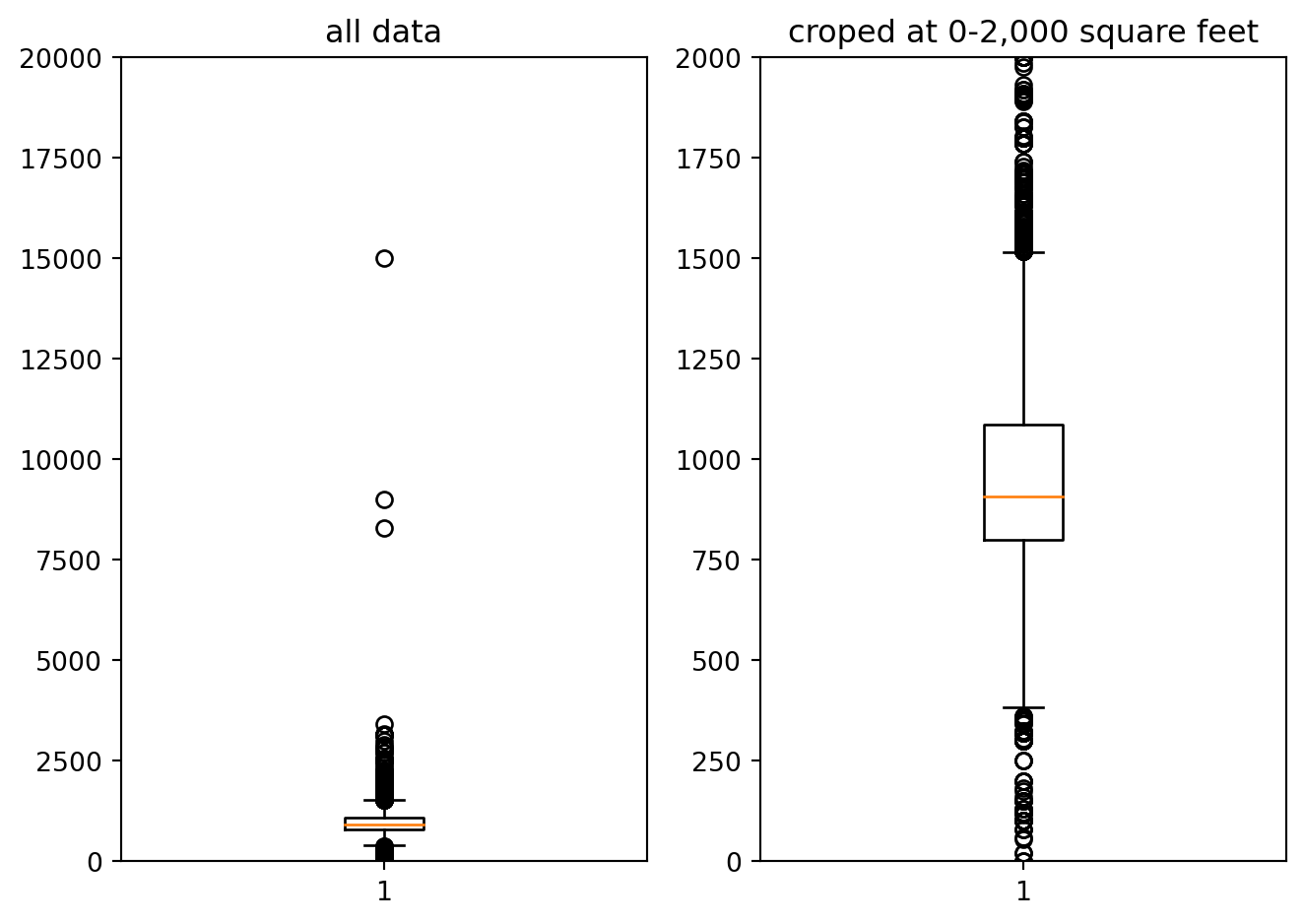
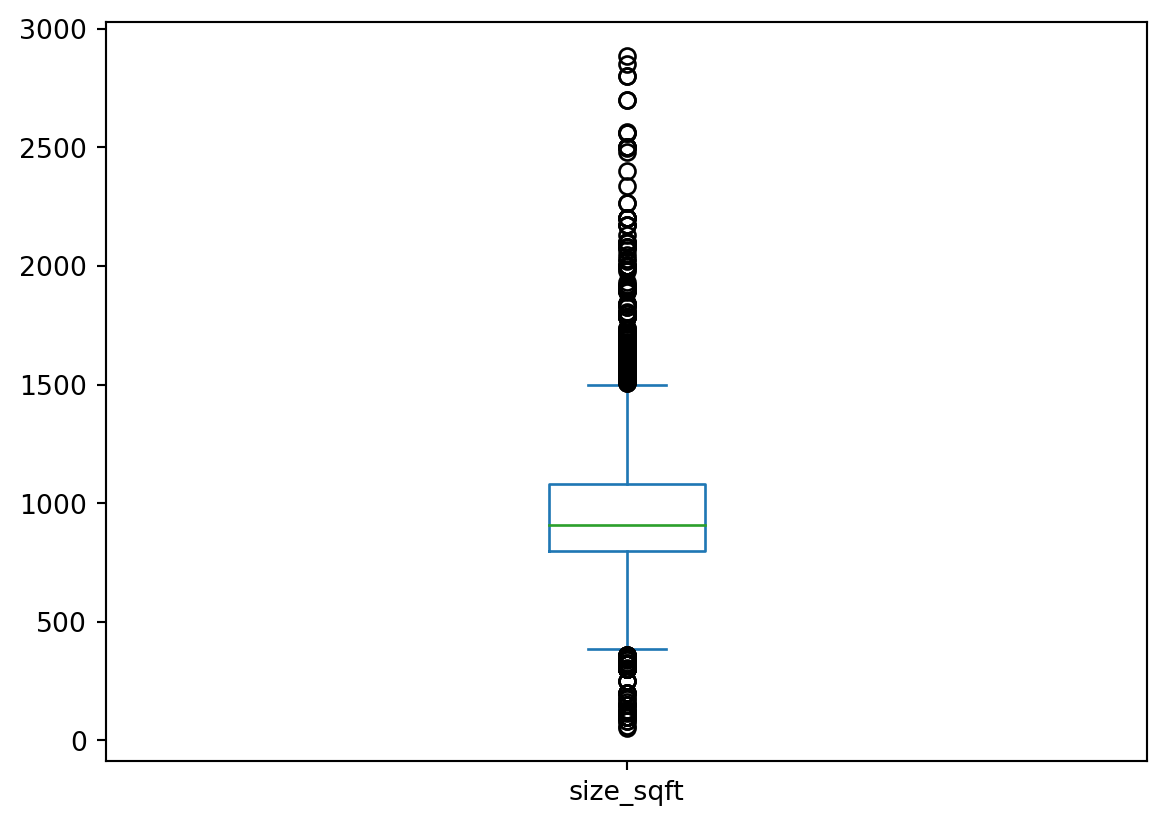
{'realValue': '1500', 'id': 'size', 'value': '1500 sq.ft.', 'label': 'Size'},
{'realValue': '1',
'id': 'furnished',
'value': 'Fully Furnished',
'label': 'Furnished'},
{'realValue': '13,9,12,7,5,16',
'id': 'facilities',
'value': 'Parking, Security, Lift, Playground, Minimart, Multipurpose hall',
'label': 'Facilities'},
{'realValue': '6200',
'id': 'rendepo',
'value': 'RM 6200',
'label': 'Rental Deposit'},
{'realValue': '1',
'id': 'additional_facilities',
'value': 'Air-Cond',
'label': 'Other Facilities'},
{'realValue': 'e', 'id': 'firm_type', 'value': 'E', 'label': 'Firm Type'},
{'realValue': '10091',
'id': 'estate_agent',
'value': '10091',
'label': 'Firm Number'}]